Data Science
April 15, 2013 – 6:47 amI just read an interesting article in the New York Times.
Universities can hardly turn out data scientists fast enough. To meet demand from employers, the United States will need to increase the number of graduates with skills handling large amounts of data by as much as 60 percent, according to a report by McKinsey Global Institute. There will be almost half a million jobs in five years, and a shortage of up to 190,000 qualified data scientists, plus a need for 1.5 million executives and support staff who have an understanding of data.
And from the McKinsey report:
To capture the full economic potential of big data, companies and policy makers will have to address the talent gap. New research by the McKinsey Global Institute (MGI) projects that by 2018, the United States alone may face a 50 to 60 percent gap between supply and requisite demand of deep analytic talent, i.e., people with advanced training in statistics or machine learning.
Machine learning techniques were one of the core analyses in my dissertation research (example below). I know that as I went deep into learning and using these methods I was struck by their power and broad generality. I realized, oh, this is what Safeway is doing with all that data they collect from my ‘rewards’ card. These techniques are a huge upgrade from the clunky and drawback-ridden multivariate techniques of the past.
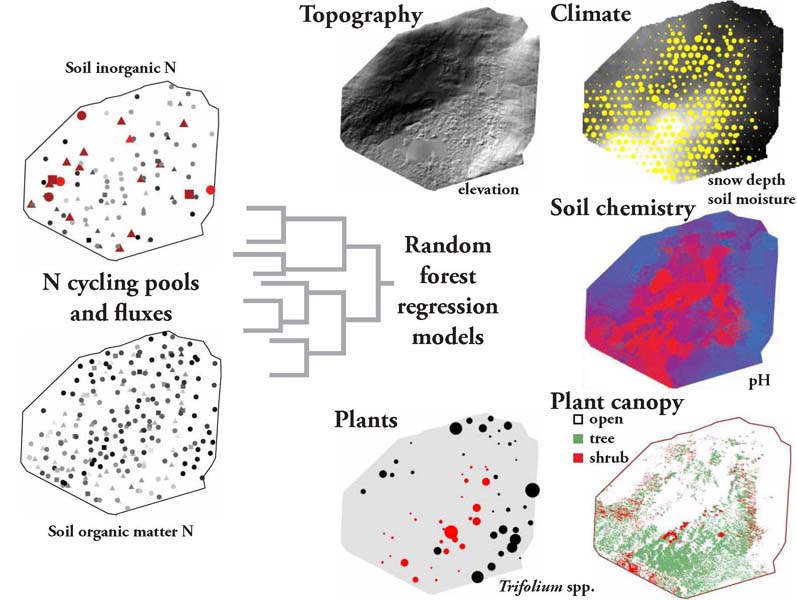
Many businesses are already reaping the rewards of using machine learning and other big data techniques, while I suspect others are just jumping in or are ramping up their operations. At the same time, public consciousness of these methods has been raised with the likes of Moneyball and Nate Silver’s entertaining pwnage of the ‘experts’ and prediction markets in the last election. Everyone is realizing, hey this stuff actually works.
People also just have reams and reams of data these days. It is axiomatic in the world of data that it is easier to collect data than to analyze, visualize, model, and interpret it. Even before interpretation, just organizing data so it can be analyzed (see this for example) is a challenge and an art that requires practice with and knowledge of concepts like normalization and map/reduce.
Once data is organized, for all but the most basic analyses, interpreting data quickly forces you into the realm of epistemology. This is the intellectual challenge that I love about statistics. You can’t just calculate mean±SE and call it a day; instead you have to ask what insights are possible, quantify how certain you are of those insights, and perhaps most importantly, define which insights are not possible. In other words, how can you extract truth from numbers without overreaching? This is a huge challenge and even with the latest techniques, pitfalls abound.
I think this critical thinking aspect of data analysis is not obvious to those with a more surface-level knowledge of statistics. Introductions to statistics tend to focus on how to “test” things, a rampant paradigm that I see as deeply problematic. For universities developing data science courses, this may also be an area where the better programs will instill the critical thinking skills while the weaker programs just teach you the latest algorithms. Either way, the students in the earliest programs seem to be doing pretty well:
North Carolina State University introduced a master’s in analytics in 2007. All 84 of last year’s graduates in the field had job offers, according to Michael Rappa, who conceived and directs the university’s Institute for Advanced Analytics. The average salary was $89,100, and more than $100,000 for those with prior work experience.
Anyway, this is cool stuff. I know I would have loved to take some data science courses when I was in school. It would have been a nice complement to all the self teaching I ended up doing out of personal interest and necessity for my research. There are so many great topics from the machine learning algorithms themselves to the Bayesian v. frequentist paradigms to more obscure stuff such as retinal variables and shrinkage.
When I was at AGU last December, I noticed that Facebook was looking to hire scientists to do this kind of work. Since the big tech companies like Facebook are at the cutting edge of implementing these methods, the fact that Facebook was trying to vacuum up talent in this area seemed to be an indicator that other companies would follow. I for one will be continuing to bone up on all of the latest tech in this area.
Sorry, comments for this entry are closed at this time.